Хранение графа: различия между версиями
Глеб (обсуждение | вклад) |
Глеб (обсуждение | вклад) |
||
| Строка 48: | Строка 48: | ||
Заметьте, что все эти способы обобщаются на случай ориентированных графов - при этом матрица смежности становится неориентированной: если есть ребро из вершины $i$ в вершину $j$, то сделаем $A_{ij} = 1$, а $A_{ji} = 0$, если только нет обратного ребра тоже. А в списке смежности в ориентированном случае при считывании ребра $(u, v)$ будем добавлять только $v$ в список соседей $u$, но не наоборот. | Заметьте, что все эти способы обобщаются на случай ориентированных графов - при этом матрица смежности становится неориентированной: если есть ребро из вершины $i$ в вершину $j$, то сделаем $A_{ij} = 1$, а $A_{ji} = 0$, если только нет обратного ребра тоже. А в списке смежности в ориентированном случае при считывании ребра $(u, v)$ будем добавлять только $v$ в список соседей $u$, но не наоборот. | ||
| + | |||
| + | {{Автор|Глеб Лобанов|glebodin}} | ||
Версия 13:20, 26 сентября 2019
Содержание
Хранение графа в программе
Чаще всего в задачах по программмированию вершины графа - это числа от $0$ до $N-1$, чтобы удобно было обращаться к ним как к индексам в разных массивах.
Также чаще всего вам дают считать граф как просто список всех рёбер в нем (но не всегда, конечно). Как оптимально считать и сохранить граф? Есть 3 способа.
Для графа существуют несколько основных способов хранения:
Матрица смежности.
Давайте хранить двумерную матрицу $A_{nn}$, где для данного графа G верно, что если $A_{ij}$ = 1, то две вершины $i$ и $j$ являются смежными, иначе вершины $i$ и $j$ смежными не являются.
Граф G и Матрица смежности :
(http://www.compendium.su/informatics/ege_1/ege_1.files/image026.jpg)
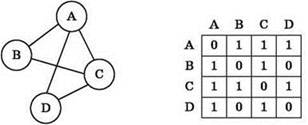{kind=link}
Мы храним для каждой из $N$ вершин информацию, есть ли ребро в другие вершины, то есть суммарно мы храним $N^2$ ячеек, а следовательно асимптотика по памяти - $O(N^2)$.
Список смежности.
Давайте для каждой из $N$ вершин хранить все смежные с ней, для этого нам потребуется любая динамическая структура, например vector в с++.
1 // как сделать список по матрице
2 vector<vector<int> > g(n);
3 for (int i = 0; i < n; ++i){
4 for (int j = 0;j < n;++j){
5 cin >> a;
6 if (a) g[i].push_back(j);
7 }
8 }
9 // список по списку ребер
10 cin >> n >> m;
11 vector<vector<int> > g(n);
12 for (int i = 0; i < m; ++i){
13 cin >> v1 >> v2;
14 g[v1].push_back(v2);
15 g[v2].push_back(v1);
16 }
Здесь асимптотика по памяти и времени считывания - $O(N + M)$, так как мы храним для каждой вершины, куда есть ребра, то есть $2 M$ ребер, а также суммарно $N$ векторов.
Плотные графы, имеющие большое количество ребер следует хранить при помощи матрицы смежности, а разреженные графы, имеющие малое количество ребер, оптимальнее при помощи списка.
Список рёбер.
Иногда граф явно вообще не требуется, а хватает хранить просто список ребер, который нам дают на вход.
Заметьте, что все эти способы обобщаются на случай ориентированных графов - при этом матрица смежности становится неориентированной: если есть ребро из вершины $i$ в вершину $j$, то сделаем $A_{ij} = 1$, а $A_{ji} = 0$, если только нет обратного ребра тоже. А в списке смежности в ориентированном случае при считывании ребра $(u, v)$ будем добавлять только $v$ в список соседей $u$, но не наоборот.
Автор конспекта: Глеб Лобанов
По всем вопросам пишите в telegram @glebodin